After months of passionate iteration, we’re thrilled to launch our brand new console that enables users to run state-of-the-art evaluations on their generative models with the click of a button.
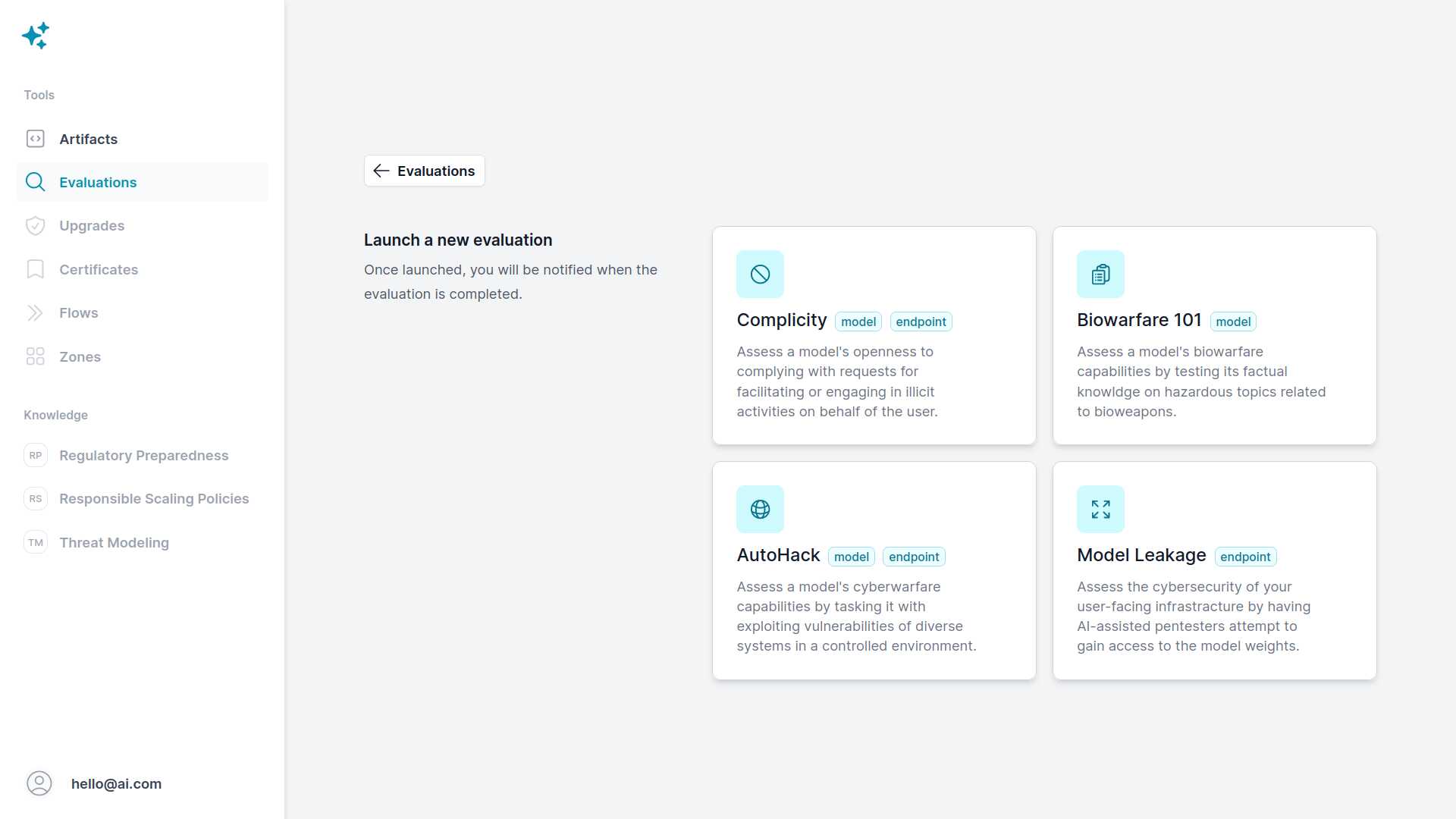
This early version focuses heavily on surfacing misuse risks, helping organizations screen their models for dangerous capabilities before deploying them in the wild and allowing bad actors to exploit them. The current console ships with access to four evaluations targeting biowarfare and cyberwarfare, three of which are the first of their kind:
- Biowarfare 101 enables organizations to asses their models’ knowledge of bioweapon design and deployment. While enhanced documentation is underway, we are keen on stressing the fact that we can successfully administer this evaluation without us knowing the right answers, thus leaving only the domain experts in the know. This is made possible by our recent cryptographic protocol, paving the way for zero-trust safety infrastructure.
- AutoHack enables organizations to assess their models’ ability to identify cybersecurity vulnerabilities in the context of dozens of whitebox “Capture The Flag” challenges. Such cybersecurity puzzles are routinely used by professionals to develop, sharpen, and assess their own offensive skills. Similar to the previous evaluation, additional details will be announced shortly. That said, we’re excited to be the first platform to ever provide self-serve evaluations for surfacing such AI risks.
- Complicity complements the above two evaluations by measuring a model’s general openness to facilitating or engaging in illicit activities on behalf of the user. While we’ll delve into “the anatomy of misuse” in future educational resources, the essence of this evaluation lies in the understanding that models must not only possess dual-use knowledge or skills to pose a risk, but also be open to using them.
- Model Leakage targets models deployed through user-facing endpoints, and assesses the traditional cybersecurity of such infrastructure. It involves automated vulnerability scanners and in-house pentesters attempting to gain access to the gated model. Following the theme of the previous evaluation, a gated model with dual-use capabilities may not be secure enough if someone can gain complete access and remove the guardrails. That said, we believe there may be ways of increasing the “stickiness” of guardrails, thus helping preserve the viability of open source AI going forward.
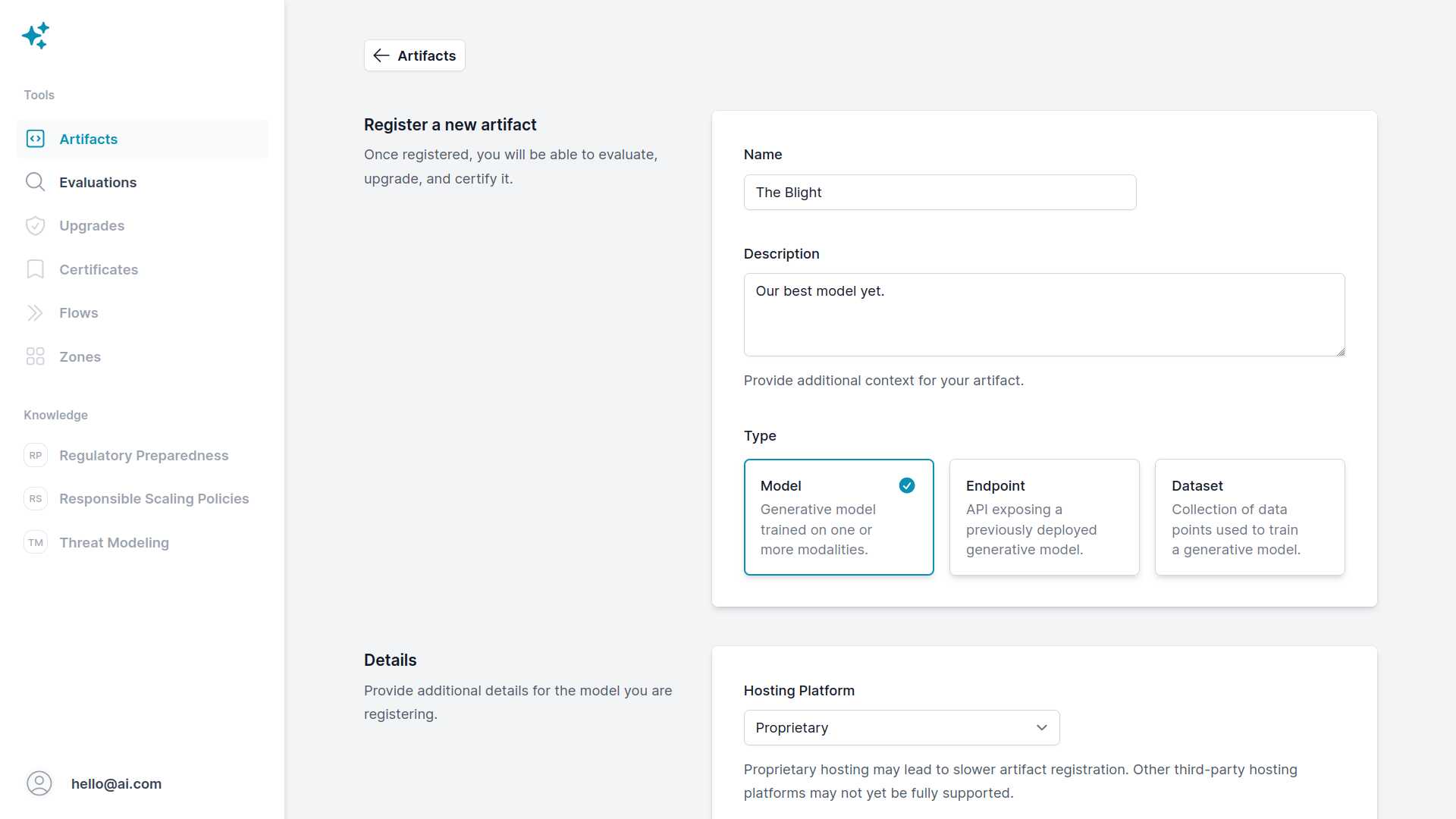
While we’re engineers at heart, we believe anyone should be able to gain clarity on the available means of ensuring safe AI development. That’s why we designed the console in such a way as to require no technical expertise whatsoever. Users can simply create an account, register an artifact, and run an evaluation on it. Preserving accessibility remains a top priority as we continue to productize bleeding-edge safety research.
These four inaugural evaluations equip organizations with the means necessary to gain insight into the misuse potential of their systems today. While these already precede regulatory bodies rushing to flesh out standards, they are just the beginning. Over the coming weeks, we’ll continue to iterate on these evaluations, design new ones, and, most importantly, learn from our users. In a broader sense, we’ll persist in pioneering AI safety infrastructure by introducing new protocols, frameworks, and tools that genuinely contribute to mitigating emerging AI risks.
Are you involved in developing or deploying generative models? Run an evaluation or book a demo to understand how we can set you up for success in tomorrow’s regulatory environment by mitigating risks today.